카테고리 없음
병합(merge)
siwoli
2022. 4. 3. 21:15
.merge(left= , right= , on=' '(left_on=' ', right_on=' '), how=' ')
merge가 SQL의 join과 같은 의미라고 책에서 설명한다.
merge함수의 매개변수를 살펴보면,
- how=
- inner join (내부 병합, 교집합 A∩B)
각각에 모두 존재하는 key값의 행끼리 병합 - full join (완전 병합, 합집합 A∪B) 동일한 key값을 가진 데이터는 통합하고, 어떤 데이터에 없는 key값은 다른 데이터에 그 key값이 있으면 남긴다.
- left join (왼쪽 병합, A)
왼쪽 테이블의 key값을 기준으로 병합 - right join (오른쪽 병합, B)
오른쪽 테이블의 key값을 기준으로 병합
- inner join (내부 병합, 교집합 A∩B)
- on='합칠때 기준으로할 열' , 합칠 두 데이터에 공통으로 존재해야한다.
- left_on='left데이터에서 기준으로 삼을 열'
- right_on='right데이터에서 기준으로 삼을 열'
* left_on과 right_on은 함께 사용해야 한다.
import pandas as pd
raw_data1 = {'subject_id': ['1','2','3','4','5','7','8','9','10','11'],
'test_score': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
raw_data2 = {'subject_id': ['4','5','6','7','8'],
'first_name': ['Billy','Brian','Bran','Bryce','Betty'],
'last_name': ['Bonder','Black','Balwner','Brice','Btisan']}
df_left = pd.DataFrame(raw_data1,columns=['subject_id','test_score'])
df_right = pd.DataFrame(raw_data2, columns=['subject_id', 'first_name','last_name'])# inner join
pd.merge(left=df_left, right=df_right, how="inner", on='subject_id')>

df_left와 df_right에 공통으로 있는 subject_id를 기준으로 병합하는데,
inner이므로 subject_id에서 공통 key값의 데이터만 반환한다.
# left join
pd.merge(df_left, df_right, on='subject_id', how='left')>

left table key값 기준으로 병합하는데, 이때 right table에 없는 값은 NaN으로 채워진다.
right join도 같은 방식이다.
# full join
pd.merge(df_left, df_right, on='subject_id', how='outer')>
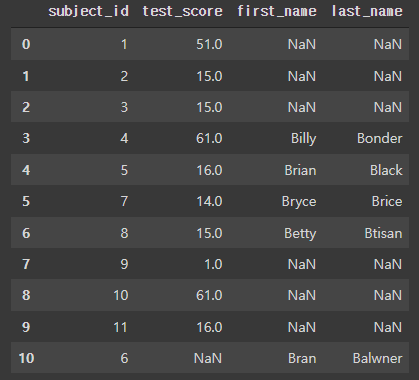
df_right에는 subject_id로 4,5,6,7,8이 있는데 6이 df_left의 subject_id에는 없으므로
다른 값들은 그대로 병합하고, 6의 데이터는 남기는 형태다.
index로 병합하기
on='index'로 두면 index를 기준으로 데이터가 병합된다.
이 방법은 index가 의미있는 것일때 사용한다.
우선 subject_id열을 index로 바꿔보자.
df_left.index = df_left.subject_id
del df_left["subject_id"]
df_right.index = df_right.subject_id
del df_right['subject_id'].index 로 subject_id열을 index열로 지정해주고 기존에 남아있는 subject_id열을 del 을 이용해 지워준다.
이때 주의할 점은 이 과정을 한번만 해야한다는 것이다. del로 지워버리기 때문에 다시하려면 df_left와 df_right를 재할당해야한다.
이어서 index가된 subject_id로 inner병합을 하면
pd.merge(df_left,df_right,on='subject_id',how='inner')>
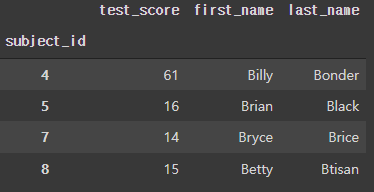
각 데이터에 공통적으로 존재하는 subject_id끼리 병합된다.