딥러닝으로 뉴진스 멤버 분류해보기
CNN(합성곱 신경망)을 배우고 어디써먹을까 생각해보다가 간단히 분류만 해보기로 했다.
요새 뉴진스의 omg에 빠져 뉴진스 멤버들을 분류해보기로 했다.
anaconda에서 실행했으며 tensorflow 2.8.2 버전을 사용했다.
먼저 구글링으로 찾은 아래의 웹크롤링 코드로 뉴진스 멤버별 셀카를 13장씩 긁어모았다.
이 코드를 실행하려면 selenium 패키지를 설치하고 chrome driver를 다운받아야 한다.
그래야 webdriver.Chrome(chrome_xxx_ driver.exe파일이 있는 경로)를 실행할수 있다.
폴더 구조는 data폴더 안에 멤버별로 폴더가 있고 그 안에 해당 멤버의 사진이 들어가는 구조다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import urllib.request
import os
search = "뉴진스 하니 셀카" # 이미지 이름
count = 13 # 크롤링할 이미지 개수
saveurl = "./newjeans/하니/" # 이미지들을 저장할 폴더 주소
## 셀레니움으로 구글 이미지 접속 후 이미지 검색
driver = webdriver.Chrome("C:/ChromeDriver_exe/chrome_109_driver.exe") #options=options
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&ogbl")
elem = driver.find_element(By.NAME, "q")
elem.send_keys(search)
elem.send_keys(Keys.RETURN)
# 페이지 끝까지 스크롤 내리기
SCROLL_PAUSE_TIME = 1
# 스크롤 깊이 측정하기
last_height = driver.execute_script("return document.body.scrollHeight")
# 스크롤 끝까지 내리기
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 페이지 로딩 기다리기
time.sleep(SCROLL_PAUSE_TIME)
# 더 보기 요소 있을 경우 클릭하기
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
#이미지 찾고 다운받기
images = driver.find_elements(By.CSS_SELECTOR, ".rg_i.Q4LuWd")
for i in range(count):
try:
images[i].click() # 이미지 클릭
time.sleep(1)
imgUrl = driver.find_element(By.CSS_SELECTOR, ".n3VNCb").get_attribute("src")
urllib.request.urlretrieve(imgUrl, saveurl + str(i) + ".jpg") # 이미지 다운
except:
pass
driver.close()왜 13장만 수집했냐면
원래는 10000장씩 수집하다가 겹치는 것도 있고 다른 사람의 사진도 있고, 여러 멤버가 같이 나온 사진도 있어
차라리 조금 퀄리티 좋은 앞부분의 사진들만 모아서 ImageDataGenerator로 이미지변환 후 증식 시키기로 했다.
수집한 13장의 사진들은 턱끝부터 정수리, 양쪽 귀만 나오게 crop했고 이는 수작업으로 진행했다.
crop한 이유는 얼굴을 제외한 부분은 noise feature가 되어 잘못된 학습을 할것이라 생각했기 때문이다.
하지만 crop도 완벽하게 하진 못했다.
그리고 첫번째 사진과 두번째사진은 항상 같은 사진이어서 실질적으로 12장의 사진을 사용했다.
그후 이미지 변환 및 증식을 진행했다. 사진 1개당 300개를 증식시켰는데, 예상 개수보다 50장 가량 적었다.
전에도 이런적이 있었는데, 아마도 이미지를 변환하면서 중복된 이미지가 만들어져 덮어씌워진 것 같다는 친구의 의견이 있었다. 정확한 이유는 찾아봐야할 것 같다.
### 이미지 변환 및 증식
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img, smart_resize
imgGen = ImageDataGenerator(rescale= 1. / 255,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.5,
zoom_range=[0.8, 2.0],
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')
for i in os.listdir("./data/"):
for k in os.listdir("./data/{}/".format(i)):
image = load_img("./data/{}/{}".format(i, k))
pix = np.array(image)
pix = pix.reshape((1, ) + pix.shape)
cnt = 0
for batch in imgGen.flow(pix,
save_to_dir='./data/{}/'.format(i),
save_prefix='{}'.format(k),
save_format='jpg') :
cnt += 1
# 300개 이미지 생성하기
if cnt > 299 :
break
이미지를 만들었으니 이제 불러와서 컴퓨터가 알아먹게 숫자로 바꿔야한다.
얼굴분류에 컬러가 중요하다고 생각해서 흑백으로 바꾸지 않고 채널을 3개로 유지한채
크기를 모두 100x100으로 통일했다. 왜 100으로 했냐면 대충 사진 몇개 크기를 보니 100이 가장 평균에 근접할 것 같아서 그랬다.
# 이미지 resize
pix_list=[]
pix_target=[]
k = 0
for k in os.listdir("./data/"):
for i in os.listdir("./data/{}".format(k)):
path = "./data/{}/{}".format(k,i)
pix = img_to_array(load_img(path))
pix = smart_resize(pix, (100, 100), interpolation="nearest")
pix = pix / 255.0
pix_target.append(k)
pix_list.append(pix)
print(len(pix_list))
pix_np = np.array(pix_list)
print(pix_np.shape)
target = np.array(pix_target)
print(target.shape)중간에 픽셀값을 255.0으로 나누는 이유는 정규화를 위해서다.
하나의 픽셀은 0~255로 색의 밝기를 나타내는데, 컴퓨터에 그대로 전달해서 계산하라하면 숫자가 너무 커 힘들어한다.
그러니 255.0으로 나눠 0~1의 값으로 정규화후 작은 값으로 만들어 컴퓨터가 계산하게 하는 것이다.
위에서 target 값은 멤버별 폴더 이름이 된다. 그런데 이를 그대로 모델에 넘겨주면 숫자 밖에 못먹는 컴퓨터가 먹뱉하기 때문에 정수 인코딩을 진행해야한다.
# target 라벨링
from sklearn.preprocessing import LabelEncoder
labeling = LabelEncoder()
label_target = labeling.fit_transform(target)
print(label_target.shape)이제 정규화시킨 이미지 하나를 확인해보자
모든 멤버 폴더들의 사진 개수 총합이 pix_np의 인덱스 범위다.
import matplotlib.pyplot as plt
plt.imshow(pix_np[3857])
이제 훈련 데이터와 검증데이터를 분류해보자
난 그냥 검증데이터를 test라고 지정했다. X_val, y_val로 이름 짓는게 더 나을것 같다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(pix_np, label_target,
test_size=0.3,
stratify=label_target,
random_state=42)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)>>>(12868, 100, 100, 3) (12868,)
>>>(5516, 100, 100, 3) (5516,)
그리고 전에 만든 간단한 구조의 CNN모델을 가져와 input_shape를 이미지 데이터에 맞게 바꾸고
최종 출력층도 멤버 수인 5로 바꿨다.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(filters=32,
kernel_size=3,
activation="relu",
padding="same",
input_shape=(100,100,3)))
model.add(tf.keras.layers.MaxPooling2D(2))
model.add(tf.keras.layers.Conv2D(64, kernel_size=(3,3),
activation='relu',
padding='same',
strides=1
))
model.add(tf.keras.layers.MaxPooling2D(2))
### 전처리계층 : 1차원으로 차원축소
model.add(tf.keras.layers.Flatten())
### hidden layer 추가
model.add(tf.keras.layers.Dense(100, activation='relu'))
model.add(tf.keras.layers.Dense(50, activation='relu'))
### 전처리 계층 추가 : dropout
model.add(tf.keras.layers.Dropout(0.3))
### 최종 출력층 추가
model.add(tf.keras.layers.Dense(5, activation='softmax'))
model.summary()>>>
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_8 (Conv2D) (None, 100, 100, 32) 896
max_pooling2d_10 (MaxPoolin (None, 50, 50, 32) 0
g2D)
conv2d_9 (Conv2D) (None, 50, 50, 64) 18496
max_pooling2d_11 (MaxPoolin (None, 25, 25, 64) 0
g2D)
flatten_6 (Flatten) (None, 40000) 0
dense_11 (Dense) (None, 100) 4000100
dense_12 (Dense) (None, 50) 5050
dropout_4 (Dropout) (None, 50) 0
dense_13 (Dense) (None, 5) 255
=================================================================
Total params: 4,024,797
Trainable params: 4,024,797
Non-trainable params: 0
_________________________________________________________________
그리고 내 노트북의 건강을 위해 callback함수와 early stopping 함수를 지정했다.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics='accuracy')
# 콜백함수 정의하기
checkpoint_cb = tf.keras.callbacks.ModelCheckpoint('./model/newjeans_model.h5')
early_stopping_cb = tf.keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)이제 훈련시켜보자
처음에는 epochs=100으로 해보니 10번째 이후부터 accuracy와 val_accuracy가 되려 감소하길래 얼른 멈추고 다시 훈련시켰다.
### 모델 훈련 시키기
history = model.fit(X_train, y_train, epochs=10, batch_size=64,
validation_data=(X_test, y_test),
callbacks=[checkpoint_cb, early_stopping_cb])>>>
Epoch 1/10
202/202 [==============================] - 85s 421ms/step - loss: 1.1698 - accuracy: 0.5040 - val_loss: 0.6044 - val_accuracy: 0.7953
Epoch 2/10
202/202 [==============================] - 85s 422ms/step - loss: 0.4124 - accuracy: 0.8547 - val_loss: 0.2005 - val_accuracy: 0.9302
Epoch 3/10
202/202 [==============================] - 86s 424ms/step - loss: 0.1526 - accuracy: 0.9535 - val_loss: 0.2403 - val_accuracy: 0.9153
Epoch 4/10
202/202 [==============================] - 89s 439ms/step - loss: 0.0789 - accuracy: 0.9744 - val_loss: 0.1084 - val_accuracy: 0.9617
Epoch 5/10
202/202 [==============================] - 83s 413ms/step - loss: 0.0576 - accuracy: 0.9827 - val_loss: 0.1126 - val_accuracy: 0.9617
Epoch 6/10
202/202 [==============================] - 86s 427ms/step - loss: 0.0499 - accuracy: 0.9855 - val_loss: 0.0597 - val_accuracy: 0.9819
Epoch 7/10
202/202 [==============================] - 84s 415ms/step - loss: 0.0309 - accuracy: 0.9902 - val_loss: 0.0699 - val_accuracy: 0.9790
Epoch 8/10
202/202 [==============================] - 84s 416ms/step - loss: 0.0250 - accuracy: 0.9919 - val_loss: 0.0731 - val_accuracy: 0.9770
훈련된 모델을 다른 test 사진으로 예측시켜보자.
test 사진들은 훈련과정에 쓰이지 않은 것들이고, 훈련에 쓰인 사진들과 같은 전처리 과정을 거쳤다. 수작업 포함이다.
## 모델불러오기
model=keras.models.load_model("./model/newjeans_model.h5")
## 이미지 불러오기
img=load_img(("./test/hani1.jpg"))
img=img.resize((100,100))
pix=np.array(img)
test_pix=pix.reshape((1,)+pix.shape)
test_pix=test_pix/255
plt.imshow(pix)
따로 메타데이터 파일은 만들지 않고 간단히 딕셔너리를 만들어 예측값 중 가장 높은 확률을 확인해봤다.
mem = {0:"다니엘", 1:"민지", 2:"하니", 3:"해린", 4:"혜인"}
pred=model.predict(test_pix)
mem[np.argmax(pred)]>>>
'하니'
다행히 잘 나온다.
이제 민지 사진을 예측시켜보자
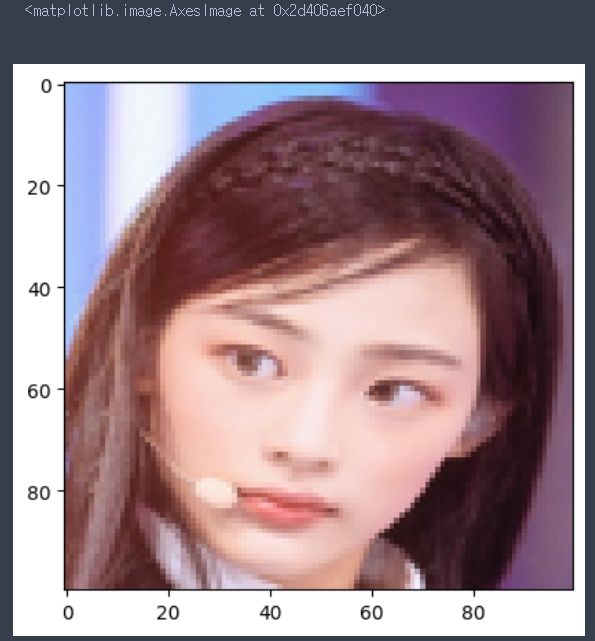

모델은 이 사진을 하니로 예측했다. 뭔가 잘못됐다.
아마도 훈련에 쓰인 이미지들이 부족했거나 노이즈가 많아 학습이 잘못됐다고 생각한다.
같은 모델을 교통 표지판 분류에 썼을 때는 매우 잘 작동했기 때문이다. 당시 학습데이터는 품질이 매우 좋았다.
garbage in garbage out을 몸소 느낀 미니 프로젝트였다.